

December 2, 2014
Why Kafka Should Run Natively on Hadoop
Apache Kafka has become an instrumental part of the big data stack at many organizations, particularly those looking to harness fast-moving data. But Kafka doesn’t run on Hadoop, which is becoming the de-facto standard for big data processing. Now a group of developers led by DataTorrent are addressing that concern with a new project called KOYA, or Kafka on YARN.
Getting Kafka into Hadoop would seem to be a no-brainer. After all, the open source message broker software already plays a critical role in many Hadoop implementations. The software, which LinkedIn released as open source in 2011, is instrumental in handling the massive flows of logs and other streaming data at companies like Spotify, Twitter, and Netflix.
Kafka is already (sort of) a part of Hadoop. In August, Hortonworks announced a tech preview of Kafka in HDP 2.1 and will deliver full support with the forthcoming launch of HDP 2.2. Hortonworks, like many big data application builders, is bullish on hooking up the reliability and scalability of Kafka’s distributed messaging system with Apache Storm, which provide real-time computational capability.
Cloudera also has worked extensively to integrate Kafka into its customers’ Hadoop implementations. The Hadoop backer even hosted Kafka creator Jay Kreps earlier this year, when he presented on Kafka at Cloudera Engineering. (MapR Technologies, which developed its Hadoop file system to continuously append files, touts the fact that it doesn’t need a system like Kafka or Flume to handle big streaming data).
The only problem with Kafka and Hadoop is that Kafka and Hadoop live in parallel worlds. While Kafka is often deployed alongside Hadoop applications, and may even exist on the same server nodes that make up a Hadoop cluster, they have no formal relationship.
The folks at DataTorrent hope to change that with Project KOYA, which it unveiled a month ago and is currently in development in the Apache Kafka community. DataTorrent hopes to place Kafka inside of Hadoop to make life easier for customers of its Hadoop-resident product, called Real Time Streaming (RTS), which provides computational capabilities for streaming data and is similar in some respects to Storm.
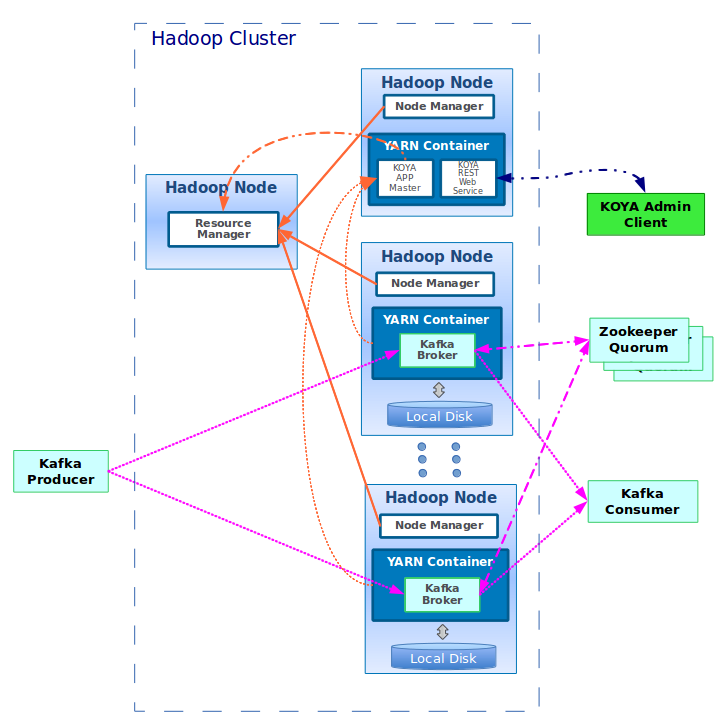
The KOYA architecture, according to DataTorrent
Getting Kafka to run natively on Hadoop via YARN is important for two reasons, explains DataTorrent’s director of product management Himanshu Bari. First, it will allow Kafka to use the computing and data resources of the Hadoop cluster. Secondly, it will simplify management of the integrated Kafka-Hadoop stack.
“When customers are running Kafka, it basically runs in its own little island,” Bari tells Datanami. “It’s not even running in Hadoop. Perhaps you can run it on the same server that you have Hadoop deployed. But it’s not really sharing the resources as such because Hadoop doesn’t know Kafka exists and Kafaka doesn’t know Hadoop exists.”
DataTorrent uses multiple data brokers to feed data into RTS, including Kafka, Flume, and JMS, among others. Kafka has proven quite popular among DataTorrent’s early customers and integrating Kafka with RTS running in Hadoop has become a priority.
“Right now Kafka runs outside of Hadoop and because of that it’s not able to share the resources of the Hadoop cluster and the data is away from the Hadoop cluster,” Bari continues. “By bringing these together, we are running Kafka and DataTorrent and Hadoop coherently on the same set of servers. It provides technical advantages as well as the simplicity of managing the Kafka cluster and reducing the cost of managing all of this different software together.”
DataTorrent is working with the Apache Kafka community to develop KOYA, which will be delivered as an optional module inside of Kafka. The company has already created a working proof of concept (POC), and hopes to have a technology preview ready for customer testing in the first quarter of 2015. You can read the full proposal of KOYA via the JIRA ticket at the Apache website for Kafka.
The company is exploring various approaches to supporting Kafka on YARN, including modifying it to run natively under YARN or using Slider. The POC took the direct approach, but the Slider approach could bring certain advantages. “I wouldn’t say [Slider is a] shortcut, but rather a better utilization of the problems that have already been solved,” Bari says. “The Slider project provides a common implementation of processes so you can reuse the processes rather than have to write it again.”
DataTorrent has contacted some of the Hadoop distributors about Koya, Bari says. “We are in the process of working with them right now,” he says. Hortonworks counts “YARN enablement” as one of its investment themes for Kafka, according to its website.
So far, DataTorrent has the backing of Kreps, who recently formed a company called Confluent to develop a Kafka-based platform for real-time data processing. “DataTorrent’s Kafka on YARN efforts makes for a great out-of-the box experience for Kafka users in the Hadoop ecosystem,” Kreps told DataTorrent. “I’m really happy to see DataTorrent betting on Kafka and contributing this to the community.”
Related Items:
LinkedIn Spinoff Confluent to Extend Kafka
LinkedIn Centralizing Data Plumbing with Kafka
LinkedIn Open Sources Samza Stream Processor
Leading Solution Providers









Tabor Network
Sponsored Multimedia








Featured Events
-
Call & Contact Center Expo
 April 24 - April 25Las Vegas NV United States
April 24 - April 25Las Vegas NV United States -
AI & Big Data Expo North America 2024
 June 5 - June 6Santa Clara CA United States
June 5 - June 6Santa Clara CA United States -
AI Hardware & Edge AI Summit 2024
 September 10 - September 12San Jose CA United States
September 10 - September 12San Jose CA United States -
CDAO Government 2024
 September 18 - September 19Washington DC United States
September 18 - September 19Washington DC United States