

August 19, 2014
If You’re Missing Fast Data, Big Data Isn’t Working for You

Big Data analytics are all the rage. There is little doubt some great things can be accomplished when an organization takes to mining its data to produce meaningful change in the business. Yet, 64 percent of enterprises that invest in Big Data projects struggle to unlock the value of their Big Data insights, according to analyst firm Gartner. A recent survey on Big Data by my company revealed that 72 percent of respondents could not utilize the majority of the data coming into their organizations. Investments in Big Data appear to be going to waste. Why?
Collecting data for exploration and analysis is good, but it is not enough. In fact, it’s not where the money is. The insights gained by all those analytic processes must be applied in real time as data from sensors, mobile, and thousands of other data points enters your organization. Acting on these streams of interactions and observations, as they are generated, requires a fast data complement to your data architecture. It is these actions – personalization, real-time contextual recommendations, fraud and security alerting, and real-time optimizations — that turn Big Data insights into increased revenue and decreased cost.
The technology required to act on individual events in real time is fundamentally different from the tools we use to store, explore and analyze petabytes of historical data. But these systems can work seamlessly together to generate the kind of return organizations have hoped for in their Big (and Fast) Data strategies.
Barriers to Fast Data Success
While reference architectures for traditional applications relying on operational databases are well understood, experience and best practices for building a complete Big Data/Fast Data architecture are still coming in to focus.
Just as new technologies like Hadoop and massively parallel processing (MPP) data warehouses have come into favor to deal with the unprecedented size of data, today’s applications also need a new technology to interact with fast streams of data as it enters the data pipeline. Because much of the data critical to a business’s success is coming in fast flows, fast ingestion of data isn’t enough.
Interacting with Fast Data
The critical question to answer is: What does processing of Fast Data require? Stated more simply, if a company is looking to gain the value from data entering the organization, what capabilities need to be in the system managing this data? After countless use cases and customer deployments of successful systems, I have come to believe there are three major capabilities that every Fast Data implementation requires:
- Ingest/interact with the data feed;
- Make decisions on each event in the feed; and
- Provide visibility into fast-moving data with real-time analytics.
As obvious as these three capabilities seem, there is tremendous value in truly understanding the power each provides to the organization that harnesses them effectively.
It’s important to note that the term “real-time analytics” is often used to refer to the speed of the response of doing a query/read from the data warehouse. This dates back to batch processing days, when a response to a query took days or hours; now the same operation takes minutes or seconds.
Because Fast + Big Data have different requirements, in a Fast Data system it’s necessary to have a component on the front end of the data architecture ingesting and interacting on data, performing real real-time analytics, making data-driven decisions on each event, enabling applications to take action, and then exporting the data to the data warehouse for historical analytics, reporting, analysis, etc. We’ll examine this in more detail below.
Ingest/interact with the data feed
When confronted with a data feed that is arriving at rates beyond historical system limits, it is easy to look for a way to limit the inbound data rate, filter the data acted upon or work on aggregates and summaries. The harsh reality, however, is that each of these tradeoffs produces a cascading degradation of the value you are getting out of the data you choose to interact with. Every time a filter is applied to limit data or an estimation is used to make a decision, that operation is not providing the value it could, and your organization suffers.
Make decisions on each event in the feed
As data enters the pipeline, thousands to millions of decisions (transactions) per second are at your disposal. You have the opportunity to make the most relevant decision to place a trade, make a shopping offer, stop an attacker or enhance a mobile experience. Each of these interactions requires interaction in real-time with data – and not just the data in that event – but also data that can enrich the interaction. This data is what provides context to your customers and satisfaction in their interaction with your systems.
Provide visibility into fast-moving data with real-time analytics
Dealing with each interaction is critical to a Fast Data strategy. Equally important is the ability to use real-time analytics in the process. Data is moving fast; trends can make meaningful impact on decisions. These trends need to be accessible to the decision-making process, all in real-time. Additionally, bringing dashboard visibility to current fast-moving data is becoming increasingly important for business managers in all industries.
Three use cases illustrate the need for the emerging corporate data architecture to take full advantage of Big Data and Fast Data:
- Making real-time decisions using fast streams of incoming data augmented by stored data – necessary to power real-time responses, personalization and segmentation and automated responses to fraud, security and infrastructure (smart grid) events;
- Enriching, augmenting and correlating data without the overhead of traditional processes like ETL, e.g. augmenting fast data flows with relatively static metadata; and
- Presenting real-time analytics and streaming aggregations to applications (and humans) – for example, dashboards, leaderboards and aggregate views of data.
The emerging Corporate Data Architecture
Fast Data requires a new data architecture that links Fast systems with Big systems. It looks like this:
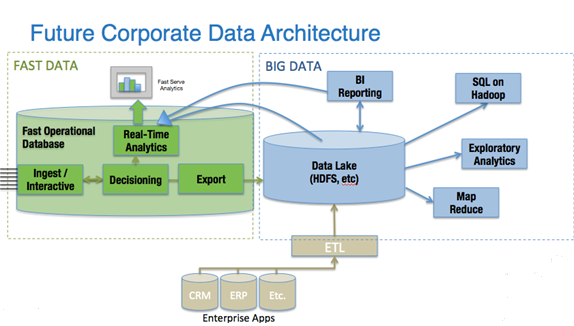
To meet the requirements of Fast Data, a high-performance operational database at the beginning of the data pipeline provides the necessary functionality of Fast. This fast front end is linked closely to the Big systems, which enable deep analysis and reporting and storage in the Data Lake. In addition to movement of data, a tight integration between Big Data and Fast Data takes care of:
- The speed mismatch between the Big system’s import capabilities and the Fast Data arrival rate;
- Reliable data transfer between Fast and Big; and
- Pre-processing of data so as it hits the Data Lake it is ready to be used (aggregating, cleaning, enriching).
Many companies have found that the missing link between fast and big lies in integration and “operationalization” of a Fast-Big, unified corporate data architecture that ties high-value, historical data from the Data Lake to high-speed incoming data from multiple endpoints. Such an architecture frees application architects from the burden of writing code, for example, to persist data as it comes into the organization and flows to the Data Lake. Moving the results of analytics stores to an in-memory operational system that can decide, analyze and serve results at Fast Data’s frequency/speed is key to making Big Data work at enterprise scale.
About the author: Scott Jarr, is co-founder and chief strategy officer at VoltDB, a provider of scale-out SQL database technology. Scott has more than 20 years of experience building, launching, and growing groundbreaking software companies, including co-founding VoltDB in 2010. Prior to VoltDB, Scott founded, served as a board member for and advised several early-stage companies in the data, mobile and storage markets. Scott has an undergraduate degree in mathematical programming from the University of Tampa and an MBA in entrepreneurship from the University of South Florida.
Related Items:
How Fast Data is Driving Analytics on the IoT Superhighway
Five Steps to Drive Big Data Agility
It’s Sink or Swim in the IoT’s Ocean of Bigger Data
Vendors:
VoltDB
Leading Solution Providers









Tabor Network
Sponsored Multimedia








Featured Events
-
AI & Big Data Expo North America 2024
 June 5 - June 6Santa Clara CA United States
June 5 - June 6Santa Clara CA United States -
AI Hardware & Edge AI Summit Europe
 June 18 - June 19London United Kingdom
June 18 - June 19London United Kingdom -
AI Hardware & Edge AI Summit 2024
 September 10 - September 12San Jose CA United States
September 10 - September 12San Jose CA United States -
CDAO Government 2024
 September 18 - September 19Washington DC United States
September 18 - September 19Washington DC United States