

July 30, 2014
How Streaming Analytics Helps Telcos Overcome the Data Deluge

Real-time streaming analytics is all the rage these days, as organizations seek to wring value from their data as quickly as possible. While the technology is bleeding edge for many, it’s commonplace in the telecommunications industry, where vendors like Guavus are leveraging the power of Hadoop and streaming analytics to help telcos not only survive the data deluge, but thrive within it.
Things are a bit different in telecommunications. While companies in other fields may experiment with new technologies, tier-one telcos and cable operators do not mess around, and demand IT solutions that are robust and scalable, hence the term “carrier grade.” Telcos were among the first organizations to begin leveraging the big data power of Hadoop and MapReduce. Many have developed their own big data analytic expertise, while others have benefited from shrink-wrapped Hadoop-based solutions from companies like Guavus.
The genesis of Guavus goes back to the early 2000s when its future founder, Anukool Lakhina, ran into a problem managing data as part of his Ph.D project in detecting network performance problems at Sprint Labs. The network sensors were throwing off data so fast that it was filling up multiple hard drives, which Lakhina then FedExed to himself for later analysis.
“At that point I realized the model for data analysis had to change on a fundamental level, especially if data was going to continue its exponential growth curve,” Lakhina says in a 2012 blog post. “Businesses needed to analyze data as the avalanche roared in, and it was going to take some sturdy tools to do it.”
The basic research into “high-dimensional data” that Lakhina conducted at Boston University would form the foundation for Guavus’ big data analytics solution, called Reflex, which today is used by some of the country’s biggest telcos, cable companies, and media companies.
Analyze First
One of the ways that Reflex gets a handle on its customers’ massive data flows is its “analyze first” approach. Instead of trying to collect and ![]() move multiple petabytes a day from sensors generating upwards of 750,000 entries per minute (or billions per day), the distributed collectors do the first analysis on the hoof, thereby stripping out the extraneous bits and sending only the most important data to the core analytic engine sitting in Hadoop.
move multiple petabytes a day from sensors generating upwards of 750,000 entries per minute (or billions per day), the distributed collectors do the first analysis on the hoof, thereby stripping out the extraneous bits and sending only the most important data to the core analytic engine sitting in Hadoop.
“We rely on collectors do the triaging of data to reduce the transfers from the edge to the core,” Ben Parker, a principal technologist at Guavus, tells Datanami in an telephone interview. “More often than not, we have the ability to collect the data right there at that location and reduce it and transport it. That’s one of the big advantages of having an analyze-first solution. At the volumes we’re talking about, that’s overwhelmingly expensive to backhaul.”
Apache Hadoop forms the core of Reflex, which drops into telco’s data centers as a virtual appliance that can be up and running in a matter of days. An in-memory Apache Spark layer is central to feeding Hadoop data from thousands of connectors that fan out to the various points in a telco’s networks. On top of Hadoop and Spark, machine learning algorithms and a columnar database provide deep analytical capabilities, while a collection of applications guide users through the process of solving specific problems.
Guavus applications supports a variety of use cases for telecos and cable companies, including detecting network outages and troubleshooting their causes; optimizing network design based on traffic bottlenecks; responding to security events; optimizing subscriber plans to increase revenue; and i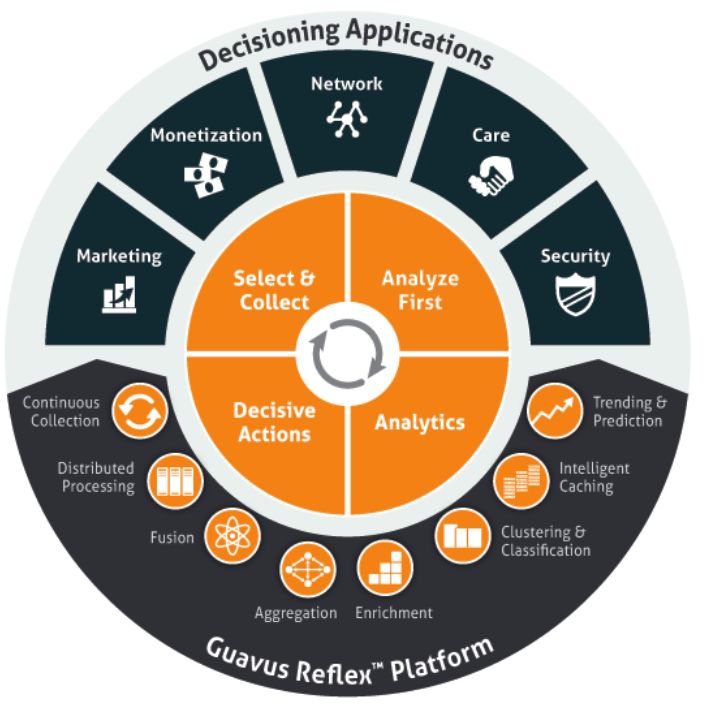 mplementing targeted mobile ad campaigns. The IT environments at telcos are incredibly large and complex. With petabytes of structured and unstructured data flying around, the parallelism of Hadoop is critical for boiling down the data and simplifying the decision-making process for humans.
mplementing targeted mobile ad campaigns. The IT environments at telcos are incredibly large and complex. With petabytes of structured and unstructured data flying around, the parallelism of Hadoop is critical for boiling down the data and simplifying the decision-making process for humans.
Responding to network outages as it occurs is a common Guavus use case. When a network outage is detected, Reflex can automatically determine what other customers are affected by that outage and proactively configure the companies’ interactive voice response (IVR) to replay a message when those specific customers call the 1-800 line for help. Considering that each truck dispatch costs the company upwards of $100, companies can save millions of dollars and bring a return on investment in a matter of months.
The capability to blend data from multiple sources—not just real-time data flows but historical data too—makes Reflex a very powerful tool for solving operational issues. For example, Reflex lets users blend server logs, SAN logs, and NetFlow results, and compare them against historical data. “We have very specific data science around root cause analysis to help pinpoint problems,” Parker says. “It’s the combination of anomaly detection and machine learning that are really key points in how we solve this problem.”
Adopting Spark
The addition of Apache Spark to the platform with the June release of Reflex 2.0 is a big deal for Guavus, which is also in the process of upgrading its first-gen Reflex customers to Hadoop version 2 and YARN.
“Spark is a huge component of this,” Parker says. “Spark’s providing the ability to do stream analysis, as well as the ability to bring data inbound into the platform. Because it’s very solid, it gives us the ability to focus on the revenue generating aspects of the business, rather than focus on making sure we have our own” real-time streaming solution.
Spark will be critical for helping Guavus to evolve the use cases for real-time analytics. “If you look back at the history of things, there has been a need to collect stream data, but not a lot of real-time, I-need-to-know-about-something-right-now type of applications,” Parker says. “Now we’re seeing applications…that are much more real time in nature, so the new platform will use Spark to take advantages of those real time uses cases and trigger-based events.”
One of the most promising new use cases is exploiting data streaming from mobile devices. Reflex can collect data natively right off the radio access network, Parker says, giving customers insight into the geographic locations of its mobile subscribers. In some cases, the data needs to be anonymized for legal reasons, in which case it can be used only for network planning. In other cases, telcos aren’t using the location data because they’re afraid it will hurt their brand. But in other places, they’re definitely starting to use this rich data source.
A final lesson in real-time data analysis to be gleaned from the telcos has to do with saying “no.” Not all data has value, and organizations need to be smart about what they keep and what they discard. In Guavus’ case, the company often keeps a running 30-day tally of the freshest data. But because much of the insight has already been extracted, customers can let the raw data expire without being afraid they’re losing anything.
Related Items:
Streaming Analytics Ready for Prime Time, Forrester Says
Want Net-New Revenue? Get Your Big Data Analytics to Go Real Time
Leading Solution Providers









Tabor Network
Sponsored Multimedia








Featured Events
-
Call & Contact Center Expo
 April 24 - April 25Las Vegas NV United States
April 24 - April 25Las Vegas NV United States -
AI & Big Data Expo North America 2024
 June 5 - June 6Santa Clara CA United States
June 5 - June 6Santa Clara CA United States -
AI Hardware & Edge AI Summit 2024
 September 10 - September 12San Jose CA United States
September 10 - September 12San Jose CA United States -
CDAO Government 2024
 September 18 - September 19Washington DC United States
September 18 - September 19Washington DC United States