

June 5, 2014
Moving Beyond ‘Traditional’ Hadoop: What Comes Next?
The phrase “traditional Hadoop” was heard early and often at this week’s 2014 Hadoop Summit. While first-generation Hadoop technologies unlocked previously unseen potential in big data sets, it pales in comparison to what we’ll see with second-gen Hadoop, we’re told.
Hope springs eternal in Silicon Valley, where tech’s brightest minds make huge fortunes changing the world and “having the courage to re-imagine the future” is a personal trait as common as liking children and small animals. So when you bring 3,200 of the Hadoop community’s best people together in the heart of Silicon Valley, it’s practically unavoidable that you’re going to come out of it with some changed perceptions about the tech industry’s hottest commodity.
The idea that there is something called “traditional Hadoop” was one of those changed perceptions. “Things are different here in the Valley,” Gartner analyst Merv Adrian quipped during his keynote Tuesday. “Where else, when you put out a release 2.0 of something, do you begin to refer to 1.0 as ‘traditional?'”

Gartner analyst Merv Adrian at Hadoop Summit this week
The gaps between Hadoop’s past, present, and future were evident at the show. In the Ghosts of Hadoop’s Past, we have MapReduce, the hardworking yet unappreciated batch technology that gave Hadoop its big break. Presently, it would seem that many of the world’s Hadoop clusters are still running MapReduce and getting good use out of it. Yahoo, which invented Hadoop nine years ago, still relies on MapReduce to process data on its massive 32,000-node cluster. (Yahoo gave Datanami an in-depth view into their Hadoop infrastructure; you can read that story here.)
But the Hadoop powers that be are eager to move past MapReduce and onto bigger and better things. The future of Hadoop is dependent on YARN, the so-called “heart” of the new data operating system, which shipped barely eight months ago with Hadoop 2. We’re still very early into Hadoop 2, but the community’s visionaries are eager to look forward–and the community, it would seem, is eager to be taken there.
Moving beyond “traditional Hadoop” will require moving beyond MapReduce. Gartner recently conducted a survey among existing Hadoop users to find out what the second most-popular most of processing on Hadoop was, after MapReduce. Adrian shared the results with his audience.
- 53 percent are doing interactive SQL
- 18 percent are running database management systems
- 14 percent are doing stream processing
- 9 percent are running search
- 6 percent are running graph applications
Obviously, SQL is on the minds of many Hadoop customers. Adrian had some advice for Hadoop customers watching Hortonworks, Cloudera, and Pivotal battle over SQL supremacy with their Impala, Hive, and HAWQ products, respectively (not to mention IBM with its Big SQL feature and Actian with ‘Vortex’). “There’s a giant battle up the road,” he said. “It’s going to be a lot of fun for next year or two. Just keep your hands on your wallet until you spend time to look at it carefully.”
Hadoop also needs to interact with traditional database management systems and even NoSQL-type database. HBase is making big inroads into the Hadoop stack, Adrian said, but even NoSQL databases, such as like MongoDB (a close Cloudera partner) are doing more in and out of Hadoop. The notion that traditional databases need to play well with Hadoop isn’t a new concept. But “Where we join [the data], where we do the processing–that’s a battleground and will continue to be,” Adrian says.
In-memory stream processing, a la Apache Spark, remains a bit green, but look for it to emerge soon, Adrian said. “You want to do things that are highly iterative that lend themselves very well to in-memory processing? Machine-learning is a great example,” he said. “Spark offers enormous opportunities. There’s a lot of work to do….This is not something you’re going to pick up off the shelf and put to work immediately. But you and vendors you buy solutions from are going to use Spark a great deal.”
Apache Storm is also carving out a niche for itself. “What if you want to process data as it’s flowing by? This is streaming event processing,” Adrian said. “There’s lot of places, particularly around the Internet of Things, where we want to do this kind of processing. This is not something we would have pointed the Hadoop stack to a year ago. But now Storm is on the horizon.”
Search is also going to be a key piece of the Hadoop 2.0 stack moving forward. “The notion that we can take the power of the Hadoop stack and wed it to what search does, and alleviate some of the problems that search has, is a very seductive one,” Adrian says. “It’s hard for most search environment to iterate over a large result set. It’s hard to join things from one to another… But it turns out that distributed computing allows us to tackle some of those problems.”
Graph processing will be here someday, Adrian promised. “We’ve been talking about it,” he said. “Today you can do graph but it’s not in the distribution. There isn’t a generally available Apache Hadoop project for graph. But stay tuned it will come. Watch for Giraph.”
The progress that the Hadoop community is making in each of these product categories is generating excitement–among users and vendors alike. Hortonworks president Herb Cunitz talked about the ease-of-integration into Hadoop that YARN brought to the table in late 2013 as creating a tipping point in the Hadoop adoption that has continued into 2014. (Hortonworks launched a YARN Ready program this week to try and accelerate its uptake among the community.)
“You can start t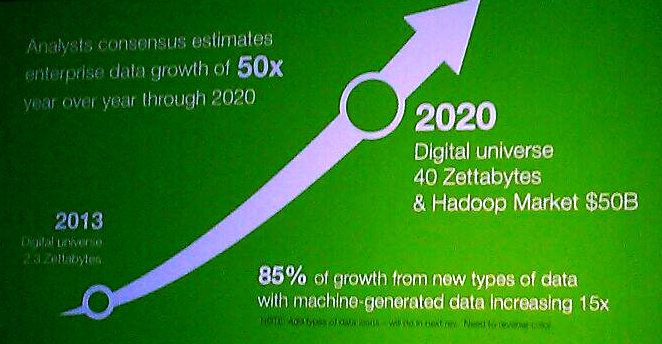 o see an inflection point in what happened in the community, what happened in the market, what happened in company’s adoption patterns as they started to look and say, ‘What else can I do with Hadoop?'” he said during his Hadoop Summit keynote. “I can do a whole lot more and leverage YARN as a data operating system and truly use Hadoop as a core data platform in my environment.”
o see an inflection point in what happened in the community, what happened in the market, what happened in company’s adoption patterns as they started to look and say, ‘What else can I do with Hadoop?'” he said during his Hadoop Summit keynote. “I can do a whole lot more and leverage YARN as a data operating system and truly use Hadoop as a core data platform in my environment.”
The power of Hadoop will be needed. According to Hortonworks CEO Rob Bearden, we’ll be facing a 50x growth in data between now and 2020, from 2.3 zetabytes in 2013 to 40 zetabytes by 2020. What’s more, 85 percent of that data is expected coming from net-new data sources, including mobile, sensor, social, web-generated data, and machine generated data, he said during his keynote address Tuesday.
“It gives us … an opportunity to build and create solutions that we’ve never been able to do,” Bearden said. “In fact, if we get that data under management correctly, it allows us to evolve the business model from being reactive post transaction to being interactive with my customers and my supply chain pre-transaction. And that’s really the value that Hadoop can bring and the genesis of Hadoop.”
Related Items:
Yahoo: We Run the Whole Company on Hadoop
Big Data is the New Engine of the Internet
Hortonworks Spins Up a YARN Readiness Program
Applications:
Data Mining
Technologies:
Middleware
Leading Solution Providers









Tabor Network
Sponsored Multimedia








Featured Events
-
Call & Contact Center Expo
 April 24 - April 25Las Vegas NV United States
April 24 - April 25Las Vegas NV United States -
AI & Big Data Expo North America 2024
 June 5 - June 6Santa Clara CA United States
June 5 - June 6Santa Clara CA United States -
AI Hardware & Edge AI Summit 2024
 September 10 - September 12San Jose CA United States
September 10 - September 12San Jose CA United States -
CDAO Government 2024
 September 18 - September 19Washington DC United States
September 18 - September 19Washington DC United States