

June 3, 2014
Actian Aims to Engulf Impala with ‘Vortex’

Actian has ported its column-oriented analytic database, Vector, to run natively on Hadoop as part of Actian Analytic Platform Hadoop Edition, better known as “Project Vortex.” Actian says parallelizing the Vector X100 engine to run on Hadoop will provide a SQL performance boost to what it already claimed was the world’s fastest database.
The new Analytic Platform Hadoop Edition combines two main products, including the Vector database to provide high-speed SQL processing, and Data Flow, which provides a graphical environment for exploring and working with data. Both products have been engineered to run natively on Hadoop via YARN.
Jim Hare, senior director of product marketing at Actian, says the duo provides a powerful one-two punch for refining raw data and serving enriched information to users. “You no longer have to be a data scientist or a guru to analyze the Hadoop data, and once you’ve analyzed it, you can provide high-performance SQL access to everybody in your organization,” he tells Datanami. “So now everybody has access to that analyzed Hadoop information.”![]()
Peter Boncz and the other Vector architects that Actian acquired from the Dutch research group CWI have been working for more than a year to get Vector (until recently known as Vectorwise) running on Hadoop. The analytics database was originally designed to run on big symmetric multi-processor (SMP) servers, so it took some tweaking to get Vector–and in particularly the vectorized query execution method–running in a scale-out, clustered mode on Hadoop.
Boncz recently blogged about what it took to get Vector running on Hadoop, and shared his thoughts about why the Vector architecture will be a good fit for Hadoop–and provide some stiff SQL competition to Cloudera’s Impala and Hortonworks with its favored SQL engine, Hive.
“Of course, it was not trivial to port Vectorwise to HDFS, but true compressed column-stores are in their access patterns quite compatible with an append-only file system that prefers large sequential I/Os (i.e. HDFS),” Boncz writes. “Unlike Hive and Impala, Vectorwise also supports fine-grained updates, since updates (at first) go to a separate data structure called the Positional Delta Tree (PDT), yet another CWI innovation. This has been an important piece the puzzle of making Vectorwise a native inhabitant of HDFS.”
Vector currently holds the speed record on the TPC-H benchmark, and may be looking to set some new records for distributed analytics databases. “We were already fast before. Now we’ve taken that same capability and allowed it to run in a multi-node environment. Just imagine how much faster it’s going to be,” Hare says.
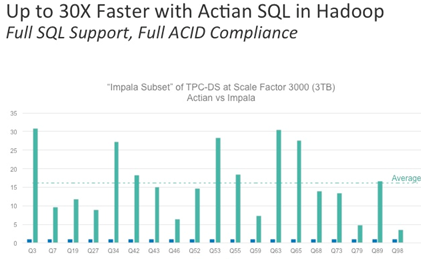
According to Actian’s chart, ‘Vortex’ runs up to 30 times faster than Impala.
Actian has already benchmarked “Vortex” against Impala in SQL processing, and found its product anywhere from 16 to 30x faster. The company plans to release a more “official” benchmark near the end of June, when the product officially becomes available.
A need for SQL speed is not the only factor here. According to Hare, the “Vortex” product also benefits from being full ANSI compliant, fully adherent to ACID precepts, and supports write-back capabilities. “We support well over 100 different types of queries in the benchmark, whereas Impala about six,” Hare says. “The story is not just about the speed, but the breadth and type of SQL that people are able to use to access Hadoop data using our approach”
Actian is firmly in the SQL side of the Hadoop camp. While SQL can’t do everything that people need, the ubiquity and familiarity that people have with it enables it to overcome some of its shortcomings working with semi-structured data.
“There are millions of people who know how to read SQL. There are very few MapReduce programmers and they’re very expensive,” Hare says. “This really unlocks a brand new audience, people who are trained and comfortable using data but who are not MapReduce programmers.”
In the battle for SQL-on-Hadoop supremacy, Actian just upped the ante.
Related Items:
Cloudera Touts Near Linear Scalability with Impala
How Actian Plans to Take Over the Big Data World
Applications:
Enterprise Analytics
Technologies:
Middleware
Leading Solution Providers









Tabor Network
Sponsored Multimedia








Featured Events
-
Call & Contact Center Expo
 April 24 - April 25Las Vegas NV United States
April 24 - April 25Las Vegas NV United States -
AI & Big Data Expo North America 2024
 June 5 - June 6Santa Clara CA United States
June 5 - June 6Santa Clara CA United States -
AI Hardware & Edge AI Summit 2024
 September 10 - September 12San Jose CA United States
September 10 - September 12San Jose CA United States -
CDAO Government 2024
 September 18 - September 19Washington DC United States
September 18 - September 19Washington DC United States