

May 1, 2014
Five Steps to Drive Big Data Agility

We are in the middle of a big data arms race that will determine the winners and the losers across many aspects of private enterprise and public life. The companies, candidates, and organizations who demonstrate the most agility in adapting to the new big data atmosphere have the best chances of surviving and succeeding in the future.
In today’s hectic digital environment, keeping up with the exponential explosion of new data is a gargantuan task. It’s no surprise that organizations need and want to make more and better use of these new data and data sources, but getting started can be tough. To remain agile, businesses need to fundamentally change the ways they think about data and approach analytics. Here are five ways organizations can start imbuing themselves with big data agility:
Step One: Create a Big Data Team
So you want to start doing stuff with big data to improve your chances of success in the big data arms race. Super! Ideally, you would hire a data scientist who has the right blend of math, statistics, business, and programming skills to lead your big data efforts. The only problem is that data scientists are tough to find and command top dollar. Universities are moving to ramp up production of data scientists, but that takes years you don’t have.
While data scientists are definitely needed for some types of big data tasks, agile organizations are finding they can still drive success with the next best thing: a big data team with a blend of technical, analytical, and business skills. In the future, business analysts and data analysts will become the main drivers of big data projects at most organizations.
George Mathew, the COO and president of analytics vendor Alteryx, says he’s seen a shift in the big data landscape toward giving business users the power to blend and analyze disparate datasets without getting IT involved. “What’s really changed across the board is that most of the folks who are actually doing the analysis in the line of business function have a much better understanding of not only their internal data sources, but what are the external data sources that can be much more seamlessly leveraged,” he recently told Datanami.
Step Two. Discard Ye Olde Data Warehousing Notions
The second step in achieving big data agility to throw out old concepts of traditional data warehousing (although not necessarily the technology; column-oriented data stores, in particular, have a bright future in big data analytics). Agile organizations do not have the luxury to take weeks or months to gather and normalize data into a data warehouse, as was historically done. This approach worked well in the past because data was mostly structured and the concept of a “single source of the truth” was actually attainable (if rarely achieved).
But the vast majority of data growth today–and most of the opportunity for exploitation, fun, and profit–is occurring with the semi-structured and unstructured data being generated by the Web, smartphones, and the Internet of Things. Hammering these truly massive data sets into a structured format is neither feasible nor desirable. A more flexible and agile approach is absolutely required. You may keep your old data warehouse around to crunch structured data from your ERP system. But it’s generally not a good idea to try to cram all your new big data sources, such as clickstream and sensor data, into the rigid (and expensive) data warehouse. Hadoop is better suited for storing this type of data.
Step Three: Scheme for Flexible Schemas
Part and parcel of moving away from old data warehousing concepts is the adoption of more agile schema-on-read methodologies, as opposed to schema-on-write or schema-on-load techqniues, which are popular in traditional data warehouses, according to Sean Kandel, the CTO at big data transformation software vendor Trifacta. “Typically when people talk about schema on write or schema on load, there’s the idea that, for a given dataset or set of datasets, the schemas–and importantly also the relationships between the datasets–are all well understood and defined at the time the data is loaded,” Kandel says.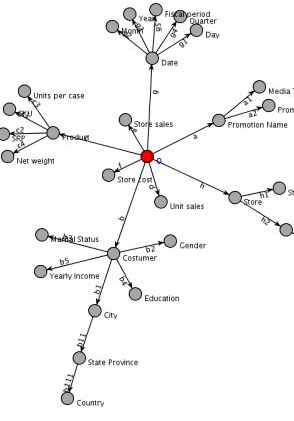
“With schema on read or schema on use, there’s the idea where we’re going to load data into the database–or, more likely, Hadoop–so we can stick data in its raw format onto the file system or the data store,” he tells Datanami. “And when an analyst has a task or somebody wants to use that data, at the time they use the data, that’s when they’ll deal with structuring the data and defining its schema and potentially defining how is this data set going to relate to other data sets in my universe of data sets.”
Step Four: Focus on Fast Data
Hadoop and NoSQL databases have brought new capacities to store and crunch massive amounts of semi-structured and unstructured data. But in many cases, the ability to process and react to fast-moving data in real time will separate agile organizations from slow-footed ones. This valuable data often originates outside of an organization, such as customers’ smart phones or a partner’s cloud application, but organizations that successfully tap into those data sources and pull out signals in real time will have an edge over those who don’t, says Thomas Been, TIBCO‘s senior director of marketing.
“We’re facing a wave of new technologies, such as sensors and mobile devices, that are a good destination of information, but also a good source of information,” Been tells Datanami. “There’s a real opportunity for organizations to find more data in which to find patterns and on which to react in real time. By cleverly using information they have in their own application and combining it with partner’s information and social network information, they can create and provide a differentiated customer experience and services.”
Step Five: Maintain Flexible Workflows
Once you’ve identified the big data sources that are going to drive your new analytic decision-making machine (perhaps residing in Hadoop, perhaps elsewhere), you need to put it all into action. Unfortunately, the day-to-day reality of the typical data analyst is often a dreary one, according to a survey of data analysts that Trifacta’s Kandel participated in at Stanford University about two years ago.
“We found that the big challenges in the agile world were not really around what’s traditionally thought of analytics–so modeling, predicting, and forecasting. Certainly there are some challenges there, especially when you to get to large-scale data,” he says. “But really the challenges were in this early phase of analysis, what we’re calling data transformation, data cleaning, data munging, or data wrangling.”
There are a number of data transformation tools, including Trifacta’s, aimed at helping organizations do the data prep work necessary for analytics without hiring people with advanced degrees in data science. As data becomes faster and more diverse, agile organizations will look to this class of tools to keep the data science aspects of big data in check, while maximizing automation and repeatability.
Related Items:
How Fast Data is Driving Analytics on the IoT Superhighway
Forget the Algorithms and Start Cleaning Your Data
Vendors:
TIBCO
Leading Solution Providers









Tabor Network
Sponsored Multimedia








Featured Events
-
Call & Contact Center Expo
 April 24 - April 25Las Vegas NV United States
April 24 - April 25Las Vegas NV United States -
AI & Big Data Expo North America 2024
 June 5 - June 6Santa Clara CA United States
June 5 - June 6Santa Clara CA United States -
AI Hardware & Edge AI Summit 2024
 September 10 - September 12San Jose CA United States
September 10 - September 12San Jose CA United States -
CDAO Government 2024
 September 18 - September 19Washington DC United States
September 18 - September 19Washington DC United States