

February 18, 2014
What Can GPFS on Hadoop Do For You?
The Hadoop Distributed File System (HDFS) is considered a core component of Hadoop, but it’s not an essential one. Lately, IBM has been talking up the benefits of hooking Hadoop up to the General Parallel File System (GPFS). IBM has done the work of integrating GPFS with Hadoop. The big question is, What can GPFS on Hadoop do for you?
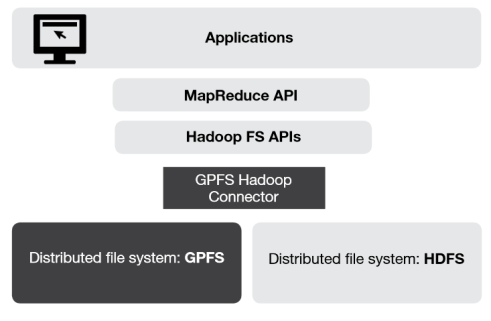 IBM developed GPFS in 1998 as a SAN file system for use in HPC applications and IBM’s biggest supercomputers, such as Blue Gene, ASCI Purple, Watson, Sequoia, and MIRA. In 2009, IBM hooked GPFS to Hadoop, and today IBM is running GPFS, which scales into the petabyte range and has more advanced data management capabilities than HDFS, on InfoSphere BigInsights, its collection of Hadoop-related offerings, as well as Platform Symphony.
IBM developed GPFS in 1998 as a SAN file system for use in HPC applications and IBM’s biggest supercomputers, such as Blue Gene, ASCI Purple, Watson, Sequoia, and MIRA. In 2009, IBM hooked GPFS to Hadoop, and today IBM is running GPFS, which scales into the petabyte range and has more advanced data management capabilities than HDFS, on InfoSphere BigInsights, its collection of Hadoop-related offerings, as well as Platform Symphony.
GPFS was originally developed as a SAN file system. That would normally prevent it from being used in Hadoop and the direct-attach disks that make up a cluster. This is where an IBM GPFS feature called File Placement Optimization (FPO) comes into play.
Phil Horwitz, a senior engineer at IBM’s Systems Optimization Competency Center, recently discussed how IBM is using GPFS with BigInsights and System x servers, and in particular how FPO has is helping GPFS to make inroads in a Hadoop cluster. (IBM has since sold off the System x business to Lenovo, which IBM now must work closely with for GPFS-based solutions, but the points are still valid).
According to Horwitz, FPO essentially emulates a key component of HDFS: moving the application workload to the data. “Basically, it moves the job to the data as opposed to moving data to the job,” he says in the interview. “Say I have 20 servers in a rack and three racks. GPFS FPO knows a copy of the data I need is located on the 60th server and it can send the job right to that server. This reduces network traffic since GPFS- FPO does not need to move the data. It also improves performance and efficiency.”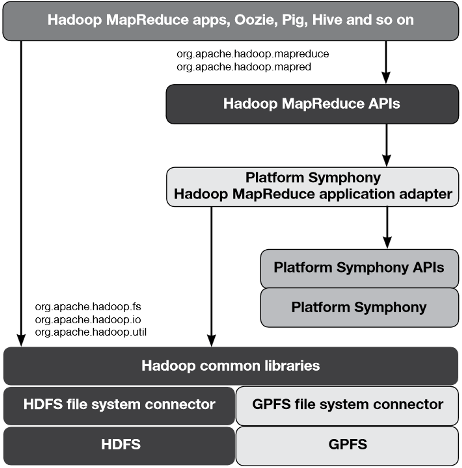
Last month, IBM published an in-depth technical white paper titled “Deploying a Big Data Solution Using IBM GPFS-FPO” that explains how to roll out GPFS on Hadoop. It also explains some of the benefits users will see from using the technology. For starters, GPFS is POSIX compliant, which enables any other applications running atop the Hadoop cluster to access data stored in the file system in a straightforward manner. With HDFS, only Hadoop applications can access the data, and they must go through the Java-based HDFS API.
The flexibility to access GPFS-resident data from Hadoop and non-Hadoop applications frees users to build more flexible big data workflows. For example, a customer may analyze a piece of data with SAS. As part of that workflow, they may use a series of ETL steps to manipulate data. Those ETL processes may be best executed by a MapReduce program. Trying to build this workflow on HDFS would require additional steps, as well as moving data in and out of HDFS. Using GPFS simplifies the architecture and minimizes the data movement, IBM says.
There are many other general IT housekeeping-type benefits to using GPFS. According to IBM’s “Harness the Power of Big Data” publication, POSIX compliance also allows users to manage their Hadoop storage “just as you would any other computer in your IT environment.” This allows customers to use traditional backup and restore utilities with their Hadoop clusters, as opposed to using the “copy” command in HDFS. What’s more, GPFS supports point-in-time snapshots and off-site replication capabilities, which aren’t available in plain-vanilla HDFS.
The size of data blocks is also an issue with HDFS. In IBM’s June 2013 whitepaper “Extending IBM InfoSphere BigInsights with GPFS FPO and IBM Platform Symphony,” IBM makes the case that, because Hadoop MapReduce is optimized for blocks that are around 64MB in size, HDFS is inefficient at dealing with smaller data sizes. In the world of big data, it’s not always the size of the data that matters; the number of data points and the frequency at which the data changes is important too.
GPFS also brings benefits in the area of data de-duplication, because it does not tend to duplicate data as HDFS does, IBM says. However, if users prefer to have copies of their data spread out in multiple places on their cluster, they can use the Write-affinity depth (WAD) feature that debuted with the introduction of FPO. The GPFS quote system also helps to control the number of files and the amount of file data in the file system, which helps to manage storage.
Capacity planning of Hadoop clusters is easier when the data stored in GPFS, IBM says. In HDFS, administrators need to carefully design the disk space dedicated to the Hadoop cluster, including dedicating space for the output of MapReduce jobs and log files. “With GPFS-FPO,” IBM says, “you only need to worry about the disks themselves filling up; there’s no need to dedicate storage for Hadoop.”
 Other benefits include the capability to used policy-based information lifecycle management functions. That means third-part management tools, such as IBM’s Tivoli Storage Manager software, can manage the data storage for internal storage pools. The hierarchical storage management (HSM) capabilities that are built into GPFS mean you can keep the “hottest” data on the fastest disks. That feature is not available in plan-vanilla Hadoop running HDFS.
Other benefits include the capability to used policy-based information lifecycle management functions. That means third-part management tools, such as IBM’s Tivoli Storage Manager software, can manage the data storage for internal storage pools. The hierarchical storage management (HSM) capabilities that are built into GPFS mean you can keep the “hottest” data on the fastest disks. That feature is not available in plan-vanilla Hadoop running HDFS.
The shared-nothing architecture used by GPFS-FPO also provides greater resilience than HDFS by allowing each node to operate independently, reducing the impact of failure events across multiple nodes. The elimination of the HDFS NameNode also eliminates the single-point-of-failure problem that shadows enterprise Hadoop deployments. “By storing your data in GPFS-FPO you are freed from the architectural restrictions of HDFS,” IBM says.
The Active File Management (AFM) feature of GPFS also boosts resiliency by caching datasets in different places on the cluster, thereby ensuring applications access to data even when the remote storage cluster is unavailable. AFM also effectively masks wide-area network latencies and outages. Customers can either use AFM to maintain an asynchronous copy of the data at a separate physical location or use GPFS synchronous replication, which are used by FPO replicas.
Security is also bolstered with GPFS. Customers can use either traditional ACLs based on the POSIX model, or network file system (NFS) version 4 ACLs. IBM says NFS ACLs provide much more control of file and directory access. GPFS also includes immutability and appendOnly restriction capabilities, which can be used to protect data and prevent it from being modified or deleted.
You don’t have to be using IBM’s BigInsights (or its Platform Symphony offering) to take advantage of GPFS. The company will sell the file system to do-it-yourself Hadoopers, as well as those who are running distributions from other companies. And using GPFS allows you to use the wide array of Hadoop tools in the big data stack, such as Flume, Sqoop, Hive, Pig, Hbase, Lucene, Oozie, and of course MapReduce itself.
IBM added the FPO capabilities to GPFS version 3.5 in December 2012. Although it’s POSIX compliant, GPFS-FPO is only available on Linux at this point. IBM says GPFS is currently being used in a variety of big data applications in the areas of bioinformatics, operational analytics, digital media, engineering design, financial analytics, seismic data processing, and geographic information systems.
Related Items:
When to Hadoop, and When Not To
Shining a Light on Hadoop’s ‘Black Box’ Runtime
Leading Solution Providers









Tabor Network
Sponsored Multimedia








Featured Events
-
AI & Big Data Expo North America 2024
 June 5 - June 6Santa Clara CA United States
June 5 - June 6Santa Clara CA United States -
AI Hardware & Edge AI Summit Europe
 June 18 - June 19London United Kingdom
June 18 - June 19London United Kingdom -
AI Hardware & Edge AI Summit 2024
 September 10 - September 12San Jose CA United States
September 10 - September 12San Jose CA United States -
CDAO Government 2024
 September 18 - September 19Washington DC United States
September 18 - September 19Washington DC United States