

February 18, 2014
Spark Graduates Apache Incubator
As we’ve touched on before, Hadoop was designed as a batch-oriented system, and its real-time capabilities are still emerging. Those eagerly awaiting this next evolution will be pleased to hear about the graduation of Apache Spark from the Apache Incubator. On Sunday, the Apache Spark Project committee unanimously voted to promote the fast data-processing tool out of the Apache Incubator.
![]() Spark was created in 2009 in University of California Berkeley’s AMPLab, and open sourced in 2010. The company formed to support Spark, Databricks, has raised nearly $14 million from venture firm Andreessen Horowitz to commercialize both Spark and its sister project, the SQL query engine Shark.
Spark was created in 2009 in University of California Berkeley’s AMPLab, and open sourced in 2010. The company formed to support Spark, Databricks, has raised nearly $14 million from venture firm Andreessen Horowitz to commercialize both Spark and its sister project, the SQL query engine Shark.
Post graduation, a project management committee will be established for the big data software, according to a report from The Register, and Databricks co-founder and CTO Matei Zaharia will take on the role of Vice President, Apache Spark.
Databricks refers to Apache Spark as “a powerful open source processing engine for Hadoop data built around speed, ease of use, and sophisticated analytics.” The computing framework supports Java, Scala, and Python and comes with a set of more than 80 high-level operators baked-in.
Spark runs on top of existing Hadoop clusters and is being pitched as a “more general and powerful alternative to Hadoop’s MapReduce.” Spark promises performance gains up to 100 times faster than Hadoop MapReduce for in-memory datasets, and 10 times faster when running on disk.
It supports SQL queries, streaming data, and complex analytics, and can also combine these capabilities by supporting multiple workloads that previously required separate engines (e.g. MapReduce, SQL and machine learning).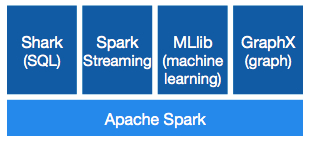
The promotion of Spark out of Apache Incubator is one more sign of a maturing Hadoop ecosystem. Where MapReduce is best suited to the high-latency batch model, Spark extends Hadoop’s viability for real-time transactional databases. The software is fully compatible with the Hadoop Distributed File System (HDFS), HBase, as well as all Hadoop storage systems. It also has built-in scripts for running on Amazon EC2.
Spark has gained traction quickly. Cloudera is shipping Spark as part of its Hadoop distro. Its active developer community includes over 100 contributors from more than 30 organizations. Users of the framework include Alibaba, Baidu, Intel, IBM’s Almaden research group, TrendMicro, Yahoo, and others companies both large and small.
The Apache site offers Spark project downloads as well as installation instructions, video tutorials, and documentation. The current version, Spark 0.9.0, was released February 2, 2014.
Related Items:
Cloudera Shuffles Its Product Deck in Pursuit of ‘Data Hub’ Strategy
Leading Solution Providers









Tabor Network
Sponsored Multimedia








Featured Events
-
Call & Contact Center Expo
 April 24 - April 25Las Vegas NV United States
April 24 - April 25Las Vegas NV United States -
AI & Big Data Expo North America 2024
 June 5 - June 6Santa Clara CA United States
June 5 - June 6Santa Clara CA United States -
AI Hardware & Edge AI Summit 2024
 September 10 - September 12San Jose CA United States
September 10 - September 12San Jose CA United States -
CDAO Government 2024
 September 18 - September 19Washington DC United States
September 18 - September 19Washington DC United States