

October 10, 2013
MarkLogic Rolls Out the Red Carpet for Semantic Triples
You write a query with great care, and excitedly hit the “enter” button, only to see a bunch of gobbledygook spit out on the screen. MarkLogic says the chances of this happening will decrease thanks to the new RDF Triple Store feature that it formally introduced today with the launch of version 7 of its eponymous NoSQL database.
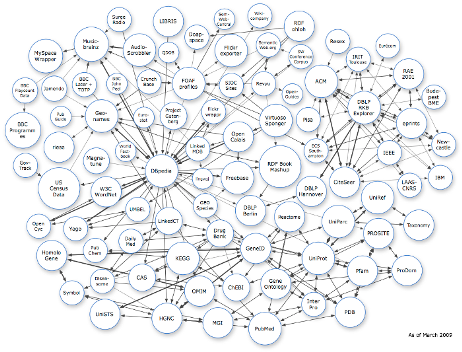
![]() The capability to store and search semantic triples in MarkLogic 7 is one of the most compelling new features of the new NoSQL database. The concept of semantic triples is central to the Resource Description Framework (RDF) way of storing and searching for information. Instead of relating information in a database using an “entity-relationship” or “class diagram” model, the RDF framework enables links between pieces of data to be searched using the “subject-predicate-object” concept, which more closely corresponds to the way humans think and communicate.
The capability to store and search semantic triples in MarkLogic 7 is one of the most compelling new features of the new NoSQL database. The concept of semantic triples is central to the Resource Description Framework (RDF) way of storing and searching for information. Instead of relating information in a database using an “entity-relationship” or “class diagram” model, the RDF framework enables links between pieces of data to be searched using the “subject-predicate-object” concept, which more closely corresponds to the way humans think and communicate.
The real power of this approach becomes evident when one considers the hugely disparate nature of information on the Internet. An RDF powered application can build links between different pieces of data, and effectively “learn” from the connections created by the semantic triples. This is the big (and as yet unrealized) pipe dream of the semantic Web.
RDF has been around for a while, and while you probably wouldn’t call it mainstream, there are a handful of applications using this approach. What makes MarkLogic’s approach unique is that it’s storing the semantic triples–the linked data–right inside the main NoSQL database, where it can make use of all the rich data and metadata stored in documents and other semi-structured files that NoSQL databases like MarkLogic are so good at storing.
This approach puts semantic triples right where it can do the most good. “Until now there has been a disconnect between the incredible potential of semantics and the value organizations have been able to realize,” states MarkLogic’s senior vice president of product strategy, Joe Pasqua.
“Managing triples in dedicated triple stores allowed people to see connections, but the original source of that data was disconnected, ironically losing context,” he continues. “By combining triples with a document store that also has built-in querying and APIs for delivery, organizations gain the insights of triples while connecting the data to end users who can search documents with the context of all the facts at their fingertips.”
MarkLogic says early adopters of MarkLogic 7 have already started playing around with the new semantic features, which uses the SPARQL query language to interrogate or infer the relationships in semantic triples. This includes the databases that powered websites created for the 2012 Summer Olympics; financial services firms that use semantic triples to manage data and risk; law enforcement organizations that use semantic triples to identify crime or fraud patterns; drug companies that use the technology to infer risk and decide which drugs to take to trial; and procurement agents, who use it to rationalized purchasing decisions.
“The semantic features we’re putting into MarkLogic have gotten a lot of interest from our user base, and even our prospect base,” MarkLogic CMO Michaline Todd told Datanami last month. “The capability to use MarkLogic as your RDF Triple Store and to use open link data helps customers to build more powerful, very textually relevant applications that deliver the exact information people need as they need it.”
Dave Schubmehl, an IDC research director in the field of search and content analytics, says the new capabilities give MarkLogic an advantage over other NoSQL database vendors, and even over traditional relational database (RDB) vendors. “While other database vendors offer limited semantic/RDF support, the combination of full XML support with robust semantic and RDF functionality and performance really makes MarkLogic a significant contender for semantic based applications and solutions,” he says via email.
Schubmehl says he sees semantic applications growing significantly. “Traditional search systems look at the ‘who,’ ‘what,’ ‘when,’ and ‘where’ in unstructured information. Government, publishers, financial services firms, and many other types of organizations are all looking to utilize semantic technologies to answer the ‘why,’ and this can only be done by finding and understanding the relationships between concepts, phrases, and keywords. This is what RDF and semantic capabilities can provide.”
MarkLogic 7 brings several other notable new features, including a new tiered storage mechanism. This gives customers the capability to use Hadoop File System (HDFS) as a storage mechanism, as well as the capability to deploy a single NoSQL database across multiple, heterogeneous, and geographically disparate platforms, including Amazon S3 and EBS.
The HDFS integration gives MarkLogic customers several configuration options. They can run the database on HDFS as a shared file system, use HDFS as a storage tier, or even use HDFS in a mixed workload scenario that combines MapReduce batch processing and real-time processing on NoSQL.
MarkLogic is one of a group of NoSQL database vendors that are trying to disrupt the market for production database systems, which for so long as been dominated by RDB vendors, like Oracle, IBM, and Microsoft. Whereas Hadoop and related tools are primarily being used for batch-oriented analytic workloads, MarkLogic and other NoSQL database vendors see themselves driving production business systems that have traditionally been powered by the RDBs.
“At many of our customers, we are the primary application,” Aaron Rosenbaum, MarkLogic’s director of product management, told Datanami last month. “At many customers, we’re the majority of the revenue they’re driving in their organization. These are almost exclusively custom applications.”
MarkLogic 7, along with the tiered storage and semantics options, are available now through the company’s early access program, and are expected to become generally available in late November.
Related Items:
Driving MapReduce into the Semantic Web
Is MarkLogic the Adult at the NoSQL Party?
Leading Solution Providers









Tabor Network
Sponsored Multimedia








Featured Events
-
Call & Contact Center Expo
 April 24 - April 25Las Vegas NV United States
April 24 - April 25Las Vegas NV United States -
AI & Big Data Expo North America 2024
 June 5 - June 6Santa Clara CA United States
June 5 - June 6Santa Clara CA United States -
AI Hardware & Edge AI Summit 2024
 September 10 - September 12San Jose CA United States
September 10 - September 12San Jose CA United States -
CDAO Government 2024
 September 18 - September 19Washington DC United States
September 18 - September 19Washington DC United States