

November 9, 2012
Twitter Flies by Hadoop on Search Quest
People who use Twitter may not give a second thought to the search bar at the top of the page. It’s pretty basic, right? You type something into the nifty little box and, like the marvel of efficient search that it is, it offers suggestions for things the user might wish to search during the typing process.
 On the surface, it operates like any decent search engine. Except, of course, this is Twitter we’re talking about. There is no basic functionality at the core here. As it turns out, a significant amount of effort went into designing the Twitter search suggestion engine and the network is still just getting started refining this engine.
On the surface, it operates like any decent search engine. Except, of course, this is Twitter we’re talking about. There is no basic functionality at the core here. As it turns out, a significant amount of effort went into designing the Twitter search suggestion engine and the network is still just getting started refining this engine.
A recent Twitter-published scientific paper tells the tale of Twitter’s journey through their previously existing Hadoop infrastructure to a custom combined infrastructure. This connects the HDFS to a frontend cache (to deal with queries and responses) and a backend (which houses algorithms that rank relevance).
The problem that faced Twitter is not dissimilar to that of Google’s real-time search: to provide suggestions which are both temporally relevant and something the particular user will want to search for. For example, if a Tweeter follows and makes plenty of tweets about football club Manchester United, that person might see “Sir Alex Ferguson” as the first suggestion on a Saturday. As they admit, Twitter’s work is not done.
The natural first step in this research was to use Twitter’s existing and sizable Hadoop infrastructure. They hoped to build their real-time search suggestion application atop their petabyte-scale Hadoop clusters. From a quality in processing standpoint, the application was working just fine. The issues rested in responding to queries in real-time.
While Hadoop provided relevant responses, the latency was too high. “The system worked reasonably in terms of output quality and allowed us to experiment and discover useful signals, but the latency was unacceptable,” the paper noted. “Related query suggestions were not available until several hours after the collection of the data those suggestions were based on.”
For example, Twitter uses Scribe, a Facebook-developed application, to record log data. Unfortunately, that log data would not make itself available to the database from which suggestions were formed for several hours. While some adjustments to Scribe made the data available in a matter of ten minutes or so, that was still an unacceptable lag time for queries that are supposed to be answered in real-time.
Another issue regarding Hadoop’s infrastructure latency was, well, Hadoop’s infrastructure. Coupled with the complex algorithms they were trying to run (which were giving good results), it would take 10-15 minutes for MapReduce jobs to run and process an hour of logs. According to the paper, “Hadoop was simply not designed for jobs that are latency sensitive.”
Ultimately, the researchers had to scrap (or at least set aside) Hadoop for providing search suggestions. The paper stated, “this does not seem quick enough—by the time we begin to make relevant related query suggestions, the breaking news event might have already passed us by.”
However, the Hadoop work was not a total loss. For one, it gave the researchers a decent quality template to look for regarding their responses. Second, they were able to find several sources of bottlenecks in the Hadoop infrastructure which make real-time processing an unrealistic goal.
Instead, Twitter incorporated a front-end technology they call a “Blender,” which essentially aggregates the user session data without the need of Scribe.
The infrastructure incorporates the algorithm on the back-end, making computations and saving them into the HDFS. To determine topics that are relevant to each other, their algorithm relies on topics found in consecutive searches or in the same tweet. As the paper noted: “The association strength between consecutive queries depends on their sources: intuitively, two hashtag clicks are not as strongly indicative as consecutive typed-in queries, and this is reflected in the incremental weight added to individual queries when a query instance is observed.” Temporal relevance is also paramount to Twitter, and their algorithm accounts for that by decreasing the weight of searches as time goes on.
The image shown below outlines the infrastructure, where the front-end in-memory caches interact with both the user and the HDFS, which interacts with the computations and serve as the liaison from the computations to the user.
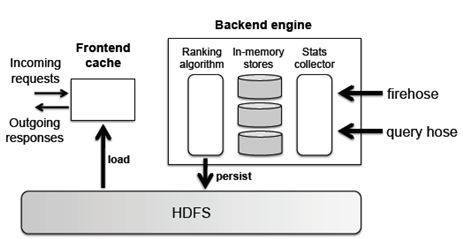
According to the paper, the fact that the data stream is singular may represent a limiting factor in the future. However, that future appears to be at least somewhat distant and as such the problem does not qualify as pressing at this time. “Since there is no partitioning of the data streams, a single server must keep up with the incoming data… In our benchmarks, CPU is not a limiting resource, and we appear to have plenty of headroom for the foreseeable future.”
Another drawback is that the Blender does not have access to clickthrough data and its data resources are limited. These are limitations that the research paper admits to needing to solve to enhance their search suggestion capabilities.
There seem to be quite a few obstacles to clear just to ensure that a Twitter user gets decent search suggestions. However, Twitter’s purpose is to provide a seemingly instantaneous social media experience, and promoting search terms based on an individual’s search history, preferences, and the current events in the world, seem like the next logical step.
Related Articles
The Algorithmic Magic of Trendspotting
Leading Solution Providers









Tabor Network
Sponsored Multimedia








Featured Events
-
Call & Contact Center Expo
 April 24 - April 25Las Vegas NV United States
April 24 - April 25Las Vegas NV United States -
AI & Big Data Expo North America 2024
 June 5 - June 6Santa Clara CA United States
June 5 - June 6Santa Clara CA United States -
AI Hardware & Edge AI Summit 2024
 September 10 - September 12San Jose CA United States
September 10 - September 12San Jose CA United States -
CDAO Government 2024
 September 18 - September 19Washington DC United States
September 18 - September 19Washington DC United States