

October 31, 2012
Infochimps Leap to Open Source Branches
During last week’s influx of big data-related news, one announcement about two growing open source projects, Kafka and Storm, caught our attention due to their prevalence in some of the web’s largest big data operations: LinkedIn and Twitter.
 The dynamic duo of Apache-driven projects is being paired with data market and big data cloud platform vendor, Infochimps, in an effort to help the company secure new golden grail, large-scale enterprise customers who need greater reliability and performance during massive data ingestion, processing and analysis.
The dynamic duo of Apache-driven projects is being paired with data market and big data cloud platform vendor, Infochimps, in an effort to help the company secure new golden grail, large-scale enterprise customers who need greater reliability and performance during massive data ingestion, processing and analysis.
This week we talked to InfoChimps co-founder, Flip Kromer and the company’s CEO, Jim Kaskade about how they plan to take the norm of on-site bare metal for big data to task with a cloud-based platform that whips up a ready environment using a range of open source and proprietary tools.
Since users can add and shut down machines according to workload, the company says the combination of this scalability with full integration and use of platforms like Hadoop can present a rather attractive ease-of-use angle to big data ingestion, management and analysis. As they try to expand into major Fortune 1000 ranks, however, the robustness of all three of these capabilities need to be backed by added reliability, fault tolerance and performance—something Kafka and Storm are able to provide.
The open source power couple, Kafka and Storm, has been matched to drive the company’s Data Delivery Service (DDS), which is at the heart of the massive data collection, transport and in-stream processing capabilities within the Infochimps Platform. Kafka is the messaging system that rolled out of LinkedIn, where it was developed to serve as the basis for their activity stream and internal operational data processing. It is also the powerhouse behind several news feeds for other social platforms, is used to aid in relevance ranking and plays a role in reporting, monitoring and batch processing across a Hadoop cluster.
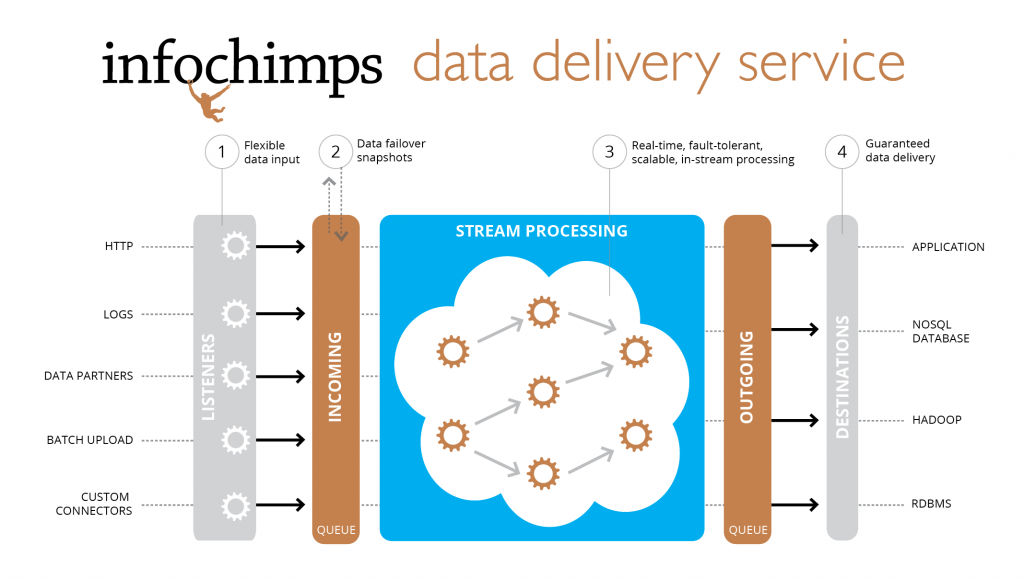
The team that developed Kafka says that the technology is central to many of the websites we visit daily. “In recent years, activity and operational data has become a critical part of the production features of websites, hence a slightly more sophisticated set of infrastructure is needed.” In this case, one that can do everything from plow through activity stream data in a snap for a range of different end uses. The problem is, they say, “This high-throughput stream of immutable activity data represents a real computational challenge as the volume may easily be 10x or 100x larger than the next largest data source on a site.”
These challenges are not so unlike what Infochimps faced as it sought to scale, add reliability and provide a dash of performance that their former Flume paradigm wasn’t able to offer. The company’s co-founder, Kromer, told us that when they started with Flume, it was the only mature(ish) platform available for the purpose. However, as they continued development, it became clear that the need for handling high volume at high speed with reliability as a critical component meant they had to look elsewhere. “It took us a while,” he said, “but we found that Flume was not the right platform for streaming data analytics; it was great for high-speed data transport, but not for what we wanted…” He notes that there was some flexibility built into Kafka that offered an “interesting, efficient take on the problem of reliable (stress reliable), high-speed data delivery into a lot of disparate systems.”
With that piece in place, he said Storm was the right fit to snap into the analytics side of their platform. For some background, Storm spun out of Twitter, which they announced last year as the answer to “open source real-time Hadoop.” The social media giant described it as a distributed, fault-tolerant, real-time computation system, which was responsible for their real-time stream processing of messages and related database updates. According to BackType, which developed it under the Twitter banner, “This is an alternative to managing your own cluster of queues and workers. Storm can be used for ‘continuous computation,’ doing a continuous query on data streams and streaming out the results to users as they are computed. It can also be used for ‘distributed RPC,’ running an expensive computation in parallel on the fly.”
As Nate Marz, the lead engineer of Storm said, the project “makes it easy to write and scale complex realtime computations on a cluster of computers, doing for realtime processing what Hadoop did for batch processing. Storm guarantees that every message will be processed. And it’s fast — you can process millions of messages per second with a small cluster. Best of all, you can write Storm topologies using any programming language.”
We chatted about these aspects of Storm and Kafka with Kaskade, who revealed that the company has been fully focused on hardening their big data platform with reliability, performance and analytics robustness this quarter. “When we looked at Storm, we saw what we needed—a guaranteed in-stream platform that let us apply analytics in motion, guaranteed strong SLAs, including replay options if there’s an error, and guaranteed fault detection and fault tolerance at linear scale.” Without these, he said that finding a way into the big enterprise world would be difficult.
“For us, it’s all about connecting data sources in motion, in real-time, and processing them in real-time in a distributed fashion that’s fault tolerant and simple,” said Kaskade. He continued, noting “we’re not looking at startups here, we’re trying to deliver to enterprises who are hungry for all that this new era of web-scale technologies offers.” He claims that these needs boil down to three main areas: in-memory processing capabilities; near real-time ad hoc querying capabilities; and batch analytic capabilities.
Next — Jumping to Higher Branches, or “Insert Awkward Metaphor Involving Franz Kafka and Severe Weather Here” >>
Co-founder Kromer expanded on this, noting that they’re well aware that the large enterprise folks they’re targeting don’t just have one set of problems to solve. They have multiple, concurrent issues and need something that scales and fits for each of the three areas Kaskade defined. “We want to stress that this isn’t some kind of different take on old ETL—it’s more than that. It’s not the thing you use to feed your analytics stack, it’s more like a tiered system. So, you do analytics using batch processing, online data stores and your real-time streaming analytics tiers. If there are things you can do in each, doing it in one stream can offer a huge amount of convenience and speed. Even when you’re not worried about the speed side, there’s a lot of power this unlocks.” He says people are often surprised by what they get done before any of the data hits the database.
Kaskade pointed to how this works in action in the context of one of their Fortune 100 customers, who analyzes 80% of their support requests that come in through the web. As users browse looking for help on the site, the system allows them, in near real-time, to use all available data about that searcher to generate a tailored, personalized set of suggestions to guide them to a solution. “That’s where Storm and Kafka come in,” he says. “You can program your analytics to look at certain things and whip out that real-time personalization.”
Of course, there’s another layer, a stratus, if you will, to how Infochimps operates. As a cloud-based company providing more than just Hadoop as a service, they have a lot of complex backend work to perform to add a layer of failover, fault tolerance and SLA guarantees given their remote status. After all, at the heart of all of this is the company’s zero-on-site hardware approach.
We asked Infochimps CEO Kaskade about the paradox of looking for big enterprise customers who tend to keep important functions on-premise, not to mention keep these operations latency-aware if it’s real-time they’re looking for anyway. He stressed that they’re making partnerships with datacenter operators, including Terremark, to ensure the ability to use private clouds, and these operators are well prepared for latency concerns.
As he told us, “Established data center providers have been partnering with Level 2 connectivity providers for a long time, enabling a direct connection between the enterprise’s own internal infrastructure and the outsourced data center provider.” Kaskade claims that this provides extremely fast, low latency data connections. The partners they’ve been working with, like SwitchNAP, have been doing this for a long time, he says, and have answered many of the connectivity and reliability questions from enterprise IT requirements – part of why they have made attractive partners. He says that these partners have already solved many of these connectivity and bandwidth challenges for enterprise applications so these concerns are not as weighty as one might think.
On this note, Kaskade continued, noting that “Part of the final deployment pattern, and solution architecture, builds on the customer’s needs anyway. By having the flexibility to deploy in an outsourced data center, private cloud, and elsewhere, we bring one of the most expansive lists of options for the enterprise when trying to balance their needs for performance and reliability.”
Spinning up the hefty infrastructure required for big data in the cloud isn’t as simple as it might sound, even with the elastic tools at everyone’s disposal. Austin-based Infochimps is taking aim at user needs to scale with and ingest massive data from multiple sources, including data streams from inside, outside or its own ever-expanding Data Marketplace as well as use Hadoop, NoSQL and a range of other approaches to get closer to real-time with deep analysis.
While the company’s Data Marketplace, which houses a collection of public and private data sets to integrate or draw from via an open API, has received a great deal of attention over the past couple of years, the Infochimps Platform is where the real meat sits for developers. Although they see some interesting movement on the horizon from new projects aiming to deliver a real-time angle to Hadoop, including Cloudera’s Impala project (Infochimps uses Cloudera’s CDH4 across the board, by the way), they say there is still a lot of work to be done as the space matures and a new competitive ecosystem around such approaches unfolds.
Vendors:
Startups and More...
Leading Solution Providers









Tabor Network
Sponsored Multimedia








Featured Events
-
Call & Contact Center Expo
 April 24 - April 25Las Vegas NV United States
April 24 - April 25Las Vegas NV United States -
AI & Big Data Expo North America 2024
 June 5 - June 6Santa Clara CA United States
June 5 - June 6Santa Clara CA United States -
AI Hardware & Edge AI Summit 2024
 September 10 - September 12San Jose CA United States
September 10 - September 12San Jose CA United States -
CDAO Government 2024
 September 18 - September 19Washington DC United States
September 18 - September 19Washington DC United States