

October 1, 2012
Quantcast Opens Exabyte-Ready File System
When ingesting data volumes that tip the multi-exabyte per year scales, even the most notorious, robust systems for managing scale can start to crumble under their own weight. When the cost and complexity of this volume mount, what’s a growing company to do but look beyond the buzz for its own solutions?
 Late last week, audience measurement and targeting giant Quantcast proved its big data user chops when it announced a new open source file system that they think presents a formidable alternative rival to the much-discussed Hadoop Distributed File System (HDFS).
Late last week, audience measurement and targeting giant Quantcast proved its big data user chops when it announced a new open source file system that they think presents a formidable alternative rival to the much-discussed Hadoop Distributed File System (HDFS).
The release, called QFS 1.0, was purpose-built to address key limitations of HDFS the team encountered as they scaled exponentially.
When we spoke about growing data volume and scaling limitations with the company’s CEO, Konrad Feldman, last week, he noted that Quantcast is in the business of addressing something in the ballpark of billions of records each month. While they have separate clusters to handle the real-time angle to their business model, the Hadoop clusters that handle the critical batch functions have always served as the foundation for their capabilities.
Quantcast’s business is big data, says Feldman, noting that they began working with Hadoop (and, of course, HDFS) since early 2006. As their ingested data volumes grew, however, he said they were forced into modifying traditional elements of the stack to improve performance and efficiency simultaneously. While the company leverages the Hadoop benefit of pure, inexpensive commodity hardware (10 GbE connected for the most part), their continuous need for growth demanded they look into tweaks that would result in savings at scale.
The company’s VP of Research and Development, Jim Kelly, drilled down the cost and performance tweak process and ultimate payoff—that is, for large-scale data clusters that are big enough that reduction in overall disk purchases would make a huge difference to the bottom line and would find it worth the disruption of shifting to a new file system (and could live without some features of HDFS like hot standby, for instance).
He explained the new file system by highlighting the evolution of the company’s tech stack as its volume and complex grew. Quantcast went from early Hadoop experimentation in 2006 to a terabyte per day a year later, and has since grown steadily to ingest around 40 terabytes per day now. Somewhere in the middle of that experiment, the cost and performance efficiencies of native Hadoop were starting to crumble, so they began evolving core elements of the stack around it. This included building a new API layer on top of the evolving stack, then rebuilding a sorter and finally addressing the real pain point—the file system.
True to its style of going “big” on a problem, the company, which had been experimenting with the Kosmos Distributed File System (KFS), brought the FS’ lead architect on board to fine-tune its approach. The architect helped the team get off the ground by moving it live onto some internal secondary storage and they began a process of investing in its development over the next few years. From that point—and up until the QFS open source release this month, he says the goals were to target scalability, reliability and cost efficiency.
Following a three-year tweak-cycle, Quantcast moved it into production under its new name, QFS, turned off HDFS, and has been operating with it at massive scale since last year. Jim Kelly says this was no easy task, but it’s managed to gobble over 4 exabytes of data since then and they’ve developed full confidence in it.
Kelly explains that from an architecture perspective, QFS looks a lot like HDFS, except the Quantcast spinoff is written in C++. Both are open source and Hadoop-compatible, but the big differences lie in the error recovery mechanisms and the added dose of parallelism that comes as a result of their refinements.

The big difference is in the error recovery mechanism. The big challenge with any distributed file system is fault tolerance. When you have 100 or 1000 or even 10k machines, you can’t expect them all to be up and running at the any given time, so being able to tolerate bits of data going missing is essentially to get any processing done. The HDFS strategy is to make three copies of all the data in hopes that there will be at least one available. That works rather well, but it’s fairly expensive because you have to buy three times as much disk space, not to mention servers to house them, racks for the servers and power to run the racks, then cooling to extract that power out of the datacenter. Naturally, at massive scale, those costs add up quickly.
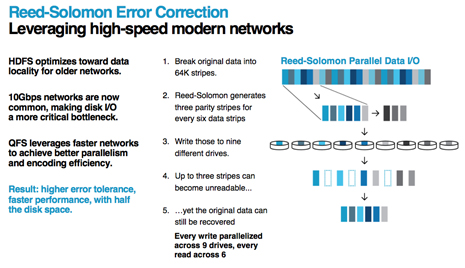
QFS leverages an entirely different approach via the Reed-Solomon error correction approach (yes, the same old-fashioned method used in CDs, DVDs and the like). The company says this ensures data availability with only 50% data expansion (compared to 200% for HDFS).
NEXT — The Error of HDFS’ Ways >
What this means is that for massive-scale datacenters, this could save a boatload of money in both disks and all of the power, cooling and space to house them. According to Kelly, the Reed-Solomon approach comes in handy here because when HDFS was created, the considerations about performance and cost were different. For instance, networks and the disk were almost tied for being the slowest components in a datacenter. Accordingly, HDFS accounted for that by optimizing for data locality via the triple-replication approach. Since that time, however, the network has become the performance powerhouse with disk still lagging behind.
What this means, explains Kelly, is that “when we write to data, we don’t write it to one place—we cut it into six stripes and calculate three parity stripes to go along with those, then rewrite those to nine distinct drives, ideally on nine different racks.” He goes on note that at read time, “we need to be able to read six of those nine, so any three can go missing so we can still recover that data.”
He says the Reed-Solomon approach is still better than triple-replication because users can afford to lose three copies. As something of a big side-effect benefit, this creates an advantage in greater parallelism—“rather than rely on one drive to read data, we’re always reading from six drives in parallel, which can improve performance…and in addition big economies of scale boosts in terms of storage efficiency since we’re only investing in half the disk space.”
The exabytes figure Quantcast operates at gives a sense of ingestion scale—but the environment speaks volumes about the data cluster as well. “We’re running on a cluster we operate ourselves—it’s an order of magnitude 1000 nodes with around 6,000 drives,” says Kelly. “We started small, but the more we grow, the more budget-conscious we need to be.” He says that anyone operating at the scale Quantcast is faces bills in the 6 to 7-figure range per month—so even the smallest tweaks, when viewed at scale—can result in massive cost differences.
To demo how this performs in some real-world context, the company undertook a benchmarking effort (using, by the way, the Cloudera distro) and found some notable improvements toward their goals of cost, performance and efficiency.
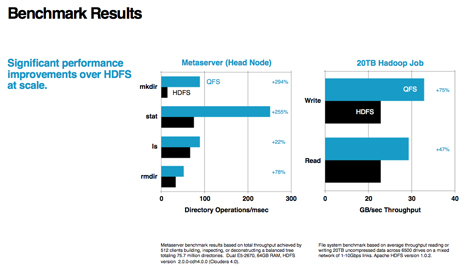
While the company was careful to note that the challenges they’ve addressed with the tweaked file system are really only going to appeal to the largest-scale operators who can experience the economies of scale the solution presents, this is noteworthy also because it offers a unique take on the ever-present, pesky problem of fault tolerance—with a side effect of increasing parallelization to reduce disk overhead.
With all this in mind, it almost seems like Quantcast is considering getting into the software business by leveraging its internal improvements to act as a side-business. One can’t help but be reminded of companies like Lexis-Nexis that built out its own Hadoop-y infrastructure that worked so well they decided to commercialize support around something that was only initially meant for internal use.
“[Software is] not our core business,” said CEO Konrad Feldman. He hopes that pushing their hard-won efforts out to the open source community will crowdsource some effort to find security and other integrity issues that only the work of an open source effort could spot. He wants QFS to grow and become more stable—and sees how the open source community, which has been at the heart of his team’s progress since 2006, can stand to gain by their commitment to giving back.
Applications:
Enterprise Analytics
Leading Solution Providers









Tabor Network
Sponsored Multimedia








Featured Events
-
AI & Big Data Expo North America 2024
 June 5 - June 6Santa Clara CA United States
June 5 - June 6Santa Clara CA United States -
AI Hardware & Edge AI Summit Europe
 June 18 - June 19London United Kingdom
June 18 - June 19London United Kingdom -
AI Hardware & Edge AI Summit 2024
 September 10 - September 12San Jose CA United States
September 10 - September 12San Jose CA United States -
CDAO Government 2024
 September 18 - September 19Washington DC United States
September 18 - September 19Washington DC United States