

May 29, 2012
The Evolution of Data Management
The rate of hardware innovation has vastly outpaced that of software – and database systems in particular. The fundamental characteristics of hardware have been revolutionized yet database architecture has not and persists with structures that date back to a bygone era.
 There have been numerous database innovations, but they have tinkered at the edges rather than solve the fundamental problems. We have seen a plethora of band aid architectures where features of the database are designed to alleviate specific performance problems rather than resolve them.
There have been numerous database innovations, but they have tinkered at the edges rather than solve the fundamental problems. We have seen a plethora of band aid architectures where features of the database are designed to alleviate specific performance problems rather than resolve them.
Indeed, the industry has largely focused on scaling hardware to overcome the performance deficiencies of databases rather resolve the fundamental hardware inefficiency.
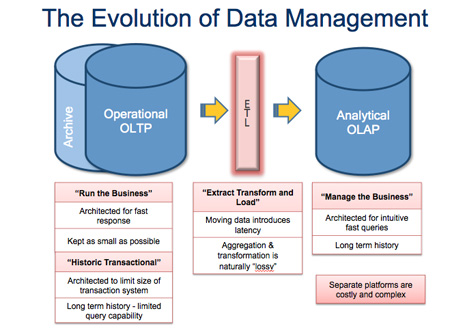
One fundamental problem with relational databases is that the way the data is stored – by row or by column – limits how the data can be used. Thus relational databases are either architected for operations or for analytics – but not both at the same time. This creates complexity and cost when delivering analytics against operational data – especially for real-time or operational analytics.
The traditional relational database is the row store, which dates back to the 1970s. Even the more recent column storage used for analytics is a concept that dates to the 1970’s.
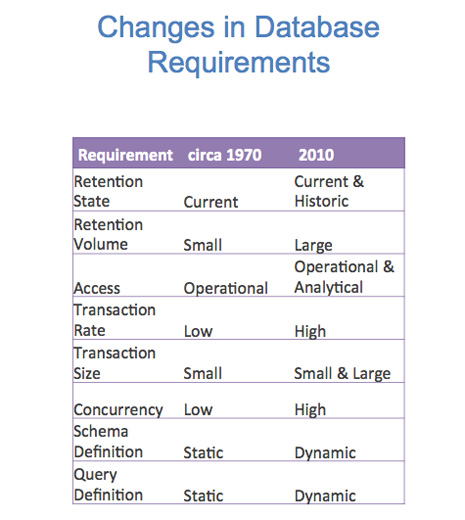
Almost any business measure you examine has radically changed since the relational database was first conceived in the 1970’s.
A database back then was largely operational and was purely responsible for providing a definitive record of the current operational state of the business. Now businesses also need to know how they got to where they are for both analytical and compliance reasons.
A very large database back then was measured in megabytes, which is now a trivial volume by comparison to the terabyte volumes that are commonplace today.
Back in the 1970’s, business intelligence was serviced by monthly or weekly summary reports. Now we see a need for both real-time and for sophisticated analytics.
Before mobile phones and the internet, transactions were driven by customer care centers with limited human bandwidth. Today many transactions are now submitted through self-service operations or autonomous device notifications and the volumes are enormous by comparison.
Next — Advances in Hardware >>
Advances in Hardware
Both the schema and the queries submitted were well defined in advance by requirements gathering using conventional waterfall design processes. That’s all changed. It’s a lot more unpredictable these days with businesses constantly optimizing their operations and rapidly responding to new trends or markets.
Back in the 1970’s, the CPU and memory were joined at the hip, such that memory was the cache for the CPU. Back then storage latency was the only performance problem and there was only a “storage wall” to overcome.

Since then, CPU speed and transfer rates have increased a thousand fold while latency in storage and memory has lagged to the point where there is now a “memory wall” to overcome as well. Memory is no longer fast enough for the CPU.
Thankfully, the speed of light remains the same – but this has important implications for data access. Whereas, in 1970, information could travel 300 metres within one CPU tick, that distance has been reduced to 100 millimetres with the increase in CPU clock speed.
If memory or storage sits further than 5cm from the CPU, then the CPU has to stall while waiting to fetch new data from it. Hence CPUs have their own cache. Even if the storage is as fast as static RAM – it will still create a storage wall if it doesn’t sit right on the motherboard alongside the CPU.
Next — The Rise of Band-Aid Architectures >>
The Rise of Band-Aid Architectures
Unsurprisingly, the last century storage structures that are still used extensively by relational databases today fail to exploit contemporary hardware and use it efficiently.
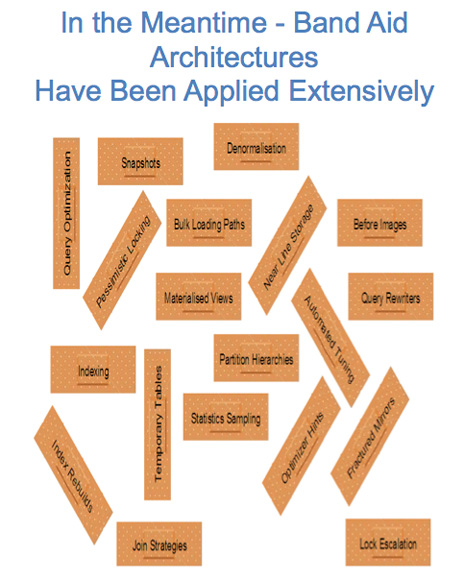
Meanwhile, the industry has focused on fixing the problem with a band aid architecture.
If indexing is slow then partition the indexes to mitigate the problem.
If loading rates are slow then provide non-transactional bulk load utilities.
If joins are too slow, then de-normalize the schema to avoid them.
None of these solutions fixes the fundamental inefficiency – it is simply a workaround.
Next — The Three Deadly Database Flaws >>
The Three Deadly Database Flaws
Databases need the solve three fundamental flaws.
 Databases are not general purpose. A row store does operations; while a column store does analytics. A row store indexed for analytics will struggle with operations. Moreover, any database becomes more specialized as more indexes are layered onto it – it becomes more adept at doing one job well and less able to perform other tasks.
Databases are not general purpose. A row store does operations; while a column store does analytics. A row store indexed for analytics will struggle with operations. Moreover, any database becomes more specialized as more indexes are layered onto it – it becomes more adept at doing one job well and less able to perform other tasks.
Databases need to become general purpose to reduce the cost and complexity that arise when organizations have dozens or hundreds of interconnected’ special-purpose’ databases.
Databases so not understand their data. Put a ton of data into a simple row store and it remains useless until you layer indexes on top of it. Column stores are only able do the most basic of aggregations until additional structures are added. Inevitably, these simplistic row and column storage models require physical design effort to make them useful. To overcome this, databases need to understand their data at a higher semantic level rather than simple physical rows, columns and data types.
Databases heavily rely on hardware scaling to overcome their performance limitations. But scaling-out adds complexity and cost and introduces new problems – such as network latency, consistency between nodes, and network bandwidth problems from distributed joins. Databases need to make more effective use of the power of the hardware and avoid unnecessary scale-out.
A relational database uses a logical schema of tables and columns to precisely reflect the application domain it is designed to serve. These logical structures are very agile – most mature relational databases allow tables and columns to be added, altered or dropped at will and instantaneously. The logical schema is responsive and can easily adapt to an evolving application.
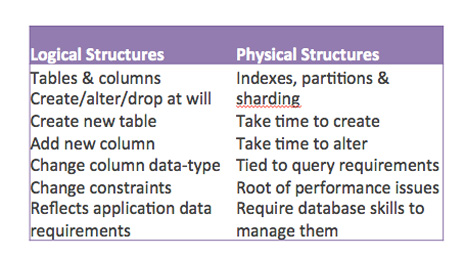
But there are also physical structures such as indexes and partitions. These are the dark underpinnings of the database and create all of the pain. Adding or altering an index or partitioning scheme can consume a huge amount of time and resources on a non trivial database. These structures make the database rigid because they create compromise and cause delays.
Next — Delivering on the Database Promise >>
Delivering on the Database Promise
An application developer should not need to concern himself with physical database design. Databases need to alleviate the pain of physical design by understanding their data better.
Databases need to align their data structures with the characteristics of contemporary hardware.
While transfer rates are fast, latency remains a big issue for both memory and storage. Data structures need to be designed to amortize latency by minimizing the number of fetch requests made to memory and storage and optimizing the size of data transferred by each request. This means providing good spatial locality whereby the majority of data required for any individual operation is co-located in storage.
Multiple cores with private caches are commonplace and they use an expensive cross-core protocol to maintain consistency between those caches . This cache coherency protocol can limit CPU performance when cores are required to share updates. Hence the data structures used by databases need to allow arbitrary and independent parallel access by multiple cores while requiring minimal synchronization and communication between CPU cores.
Databases need to separate their storage structure from the data model use by the developer. The database storage does not need to be hardwired into providing a relational, object or key-value data model view of the world. The data model should just be a convenient view in which a developer chooses to work – meanwhile the database can handle the translation between the developer view of the data and its physical structure.
This would allow multiple models to coexist against the same data and obviate the debate about the best use of relational vs. NoSQL databases.
Scale-out is a necessary strategy to deal with unlimited data volumes and database activity. But while scale-out solves a limited set of performance problems it brings its own challenges, including added latency, bandwidth limitations, consistency issues and cost and complexity. These problems mostly arise from physical constraints and are inevitable. Hence scale-out is best treated as a solution of last resort rather than an option of first choice.
However, in scaled-out environments, transactions need to be able to choose what guarantees they require – rather than enforcing or relaxing ACID constraints across a whole database. Each transaction should be able to decide how synchronous, atomic or durable it needs to be and how it must interact with other transactions. For example, must a transaction be applied in chronological order or can it be allowed out of time order with other transactions providing the cumulative result remains the same? Not all transactions need be rigorously ACID and likewise not all transactions can afford to be non-atomic or potentially inconsistent.
Hardware will continue to evolve and databases need to follow the trends.
Cores will continue to proliferate and databases need to become inherently parallel within a single server. This needs to be treated as a shared-nothing scaling problem within a single CPU because unnecessary communication between cores will throttle performance.
SSD has brought storage speeds closer to that of memory. Meanwhile large non-volatile memory is a technology in development and is probably only a few years away from commercialization. The distinction between storage and memory will eventually disappear and that will change the way applications want to interact with a database and databases will need to adapt accordingly.
But even with non-volatile memory – the problem of the memory wall will remain for some time and will continue to govern performance limitations.
Applications:
Enterprise Analytics
Leading Solution Providers









Tabor Network
Sponsored Multimedia








Featured Events
-
AI & Big Data Expo North America 2024
 June 5 - June 6Santa Clara CA United States
June 5 - June 6Santa Clara CA United States -
AI Hardware & Edge AI Summit Europe
 June 18 - June 19London United Kingdom
June 18 - June 19London United Kingdom -
AI Hardware & Edge AI Summit 2024
 September 10 - September 12San Jose CA United States
September 10 - September 12San Jose CA United States -
CDAO Government 2024
 September 18 - September 19Washington DC United States
September 18 - September 19Washington DC United States